(서울=뉴스1) 김민석 기자
"지브리 스타일로 프로필을 바꾸면서 문득 오픈AI가 수집한 사진의 얼굴 데이터를 인공지능(AI) 학습에 이용하는 건 아닌가 싶더라고요. 사람들이 자발적으로 개인 고유 데이터를 제공하는 셈인데 기업이 이 기회를 놓치지 않을 것으로 생각하니 한편으로 섬뜩합니다."
챗GPT의 이미지 생성 기능이 폭발적 인기를 지속하면서 오픈AI가 수집한 이용자 사진(얼굴) 데이터를 AI 학습에 이용할 수 있다는 우려가 나온다.
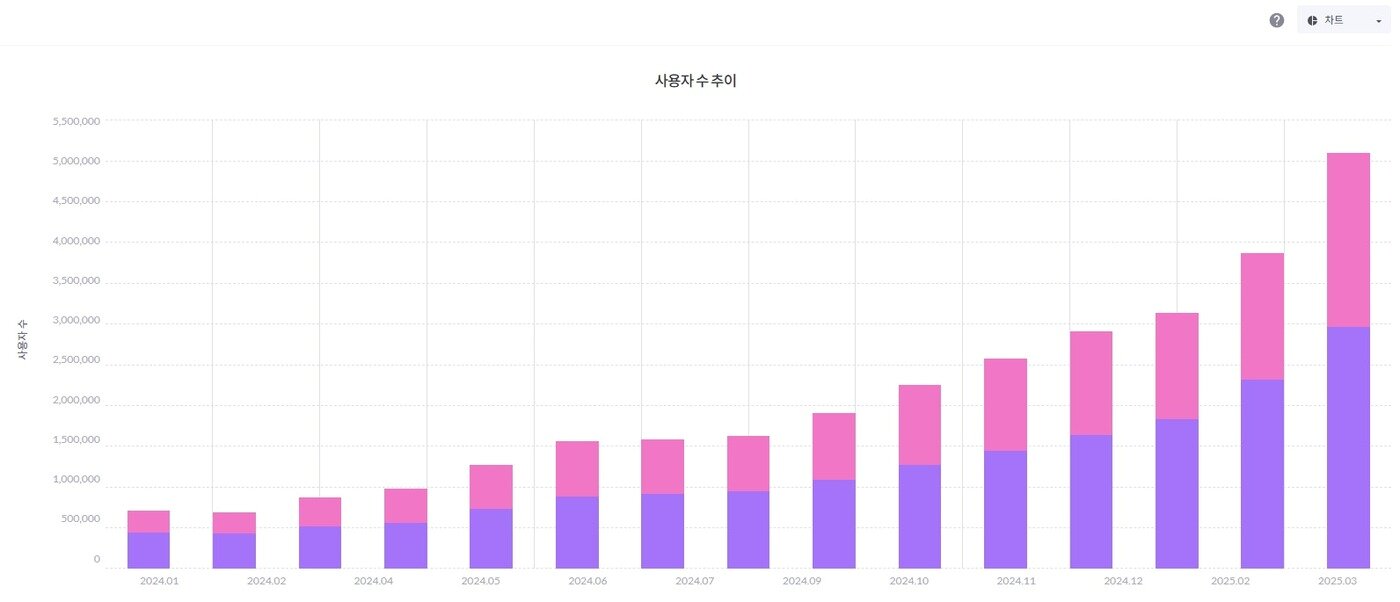
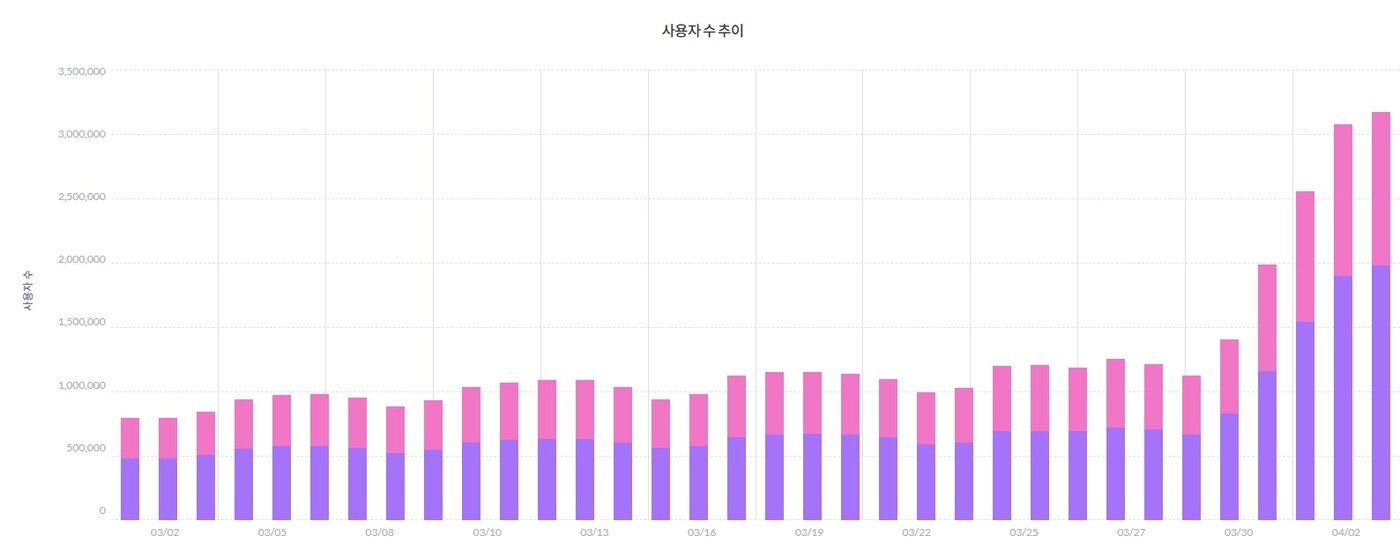
8일 아이지에이웍스 모바일인덱스에 따르면 올해 3월 국내 챗GPT 월간 활성 이용자 수(MAU)는 전월(386만 9088명) 대비 31.6% 증가한 509만 965명으로 역대 최대치를 기록했다. 전년 동기(88만 명) 대비로는 478.4% 상승했다.
일간 활성 이용자 수(DAU)도 지브리 스타일 유행 일주일 만에 125만 명에서 308만 명대로 2.5배 늘었다.
이들이 자신 또는 가족·친구 사진을 첨부한 후 이미지 변환 요청을 한 번씩 했다고 가정해도 오픈AI는 약 200만~300만 명의 한국인 사진을 축적했을 것으로 추정된다.
글로벌 단위에선 수억 개 규모의 얼굴 사진을 확보했을 것으로 분석된다. 오픈AI COO는 최근 X(옛 트위터)를 통해 "1억 3000만 명 이상의 이용자가 7억 개 이상의 이미지를 생성했다"고 밝힌 바 있다.
일부 이용자는 업로드한 사진이 AI 학습에 활용되거나 특정 목적에 쓰이는 건 아닌지 우려하고 있다.
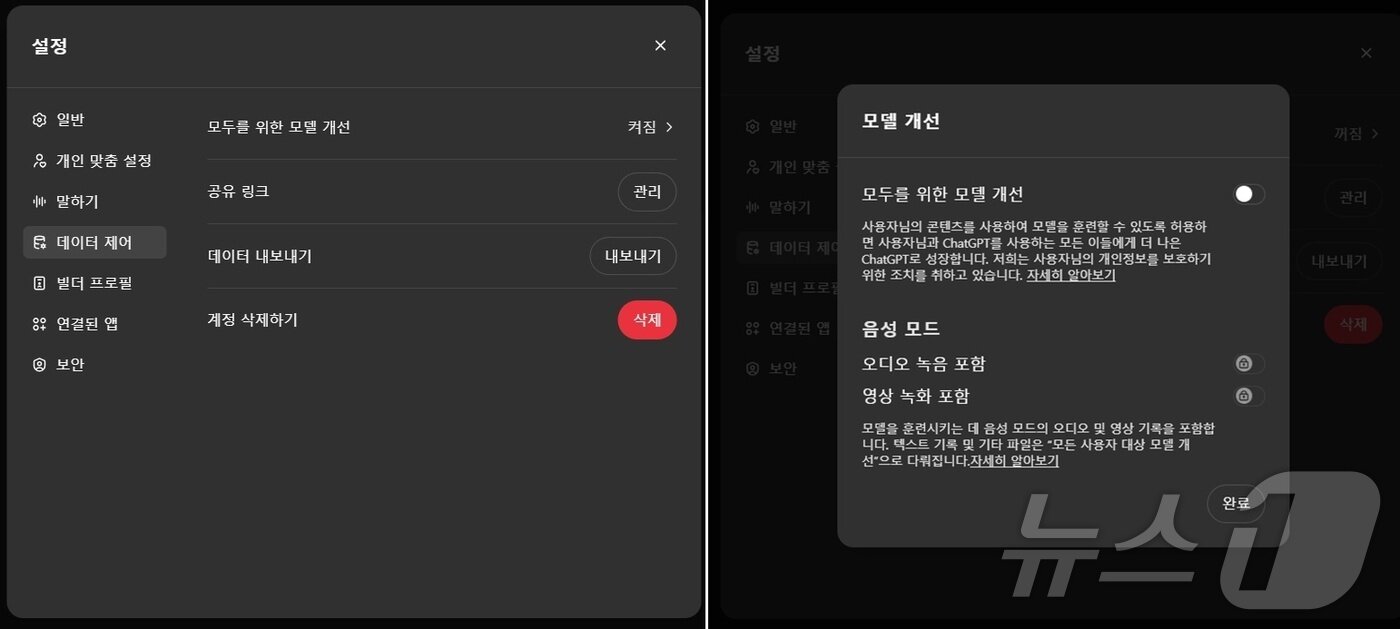
실제로 오픈AI 개인정보 처리방침에 따르면 이용자(무료 또는 플러스·프로 구독자 한정)가 입력한 프롬프트와 업로드한 모든 콘텐츠(이미지·오디오·영상 등)는 데이터 수집 대상으로 오픈AI는 이를 서비스 개선에 이용할 수 있다고 명시했다.
이용자는 챗GPT '설정'-'데이터 제어'에서 '모델 개선' 항목 활성화(기본 값) 상태를 확인할 수 있다. 이용자는 'AI 챗봇 개인 맞춤 개선'을 포기하는 조건으로 자신의 데이터를 AI 학습·훈련에 사용하지 못하도록 설정을 변경할 수 있다.

전문가는 민감한 개인 사진은 업로드를 자제하고 데이터 제공 차단 설정을 활용할 것을 권장했다.
오픈AI가 초상권법을 포함한 각종 법 위반 가능성을 고려해 수집한 사진 데이터를 직접 활용하는 서비스를 내놓거나 광고 등 수익 사업에 활용하진 않겠지만, AI가 대규모 이미지 데이터에 접근해 학습할 가능성은 있다고 분석했다.
허윤 변호사(법무법인 동인)는 "오픈AI 입장에선 다양한 연령·인종·성별의 얼굴 이미지 데이터를 축적할 수 있었을 것"이라며 "재미 삼아 사진을 업로드했다가 개인의 민감 정보가 유출될 수 있는 만큼 이를 원하지 않는다면 데이터 학습 차단 설정을 해둬야 한다"고 말했다.
ideaed@news1.kr