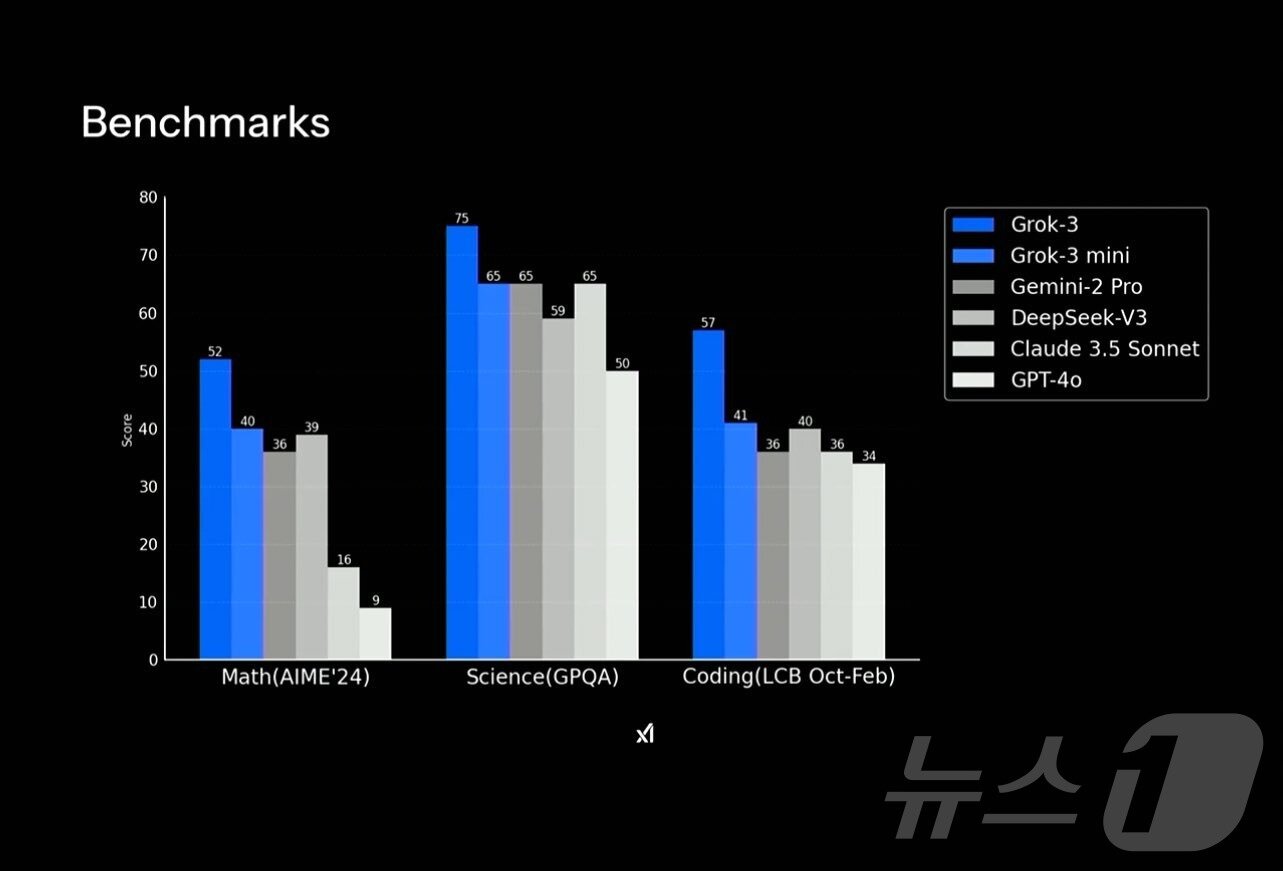
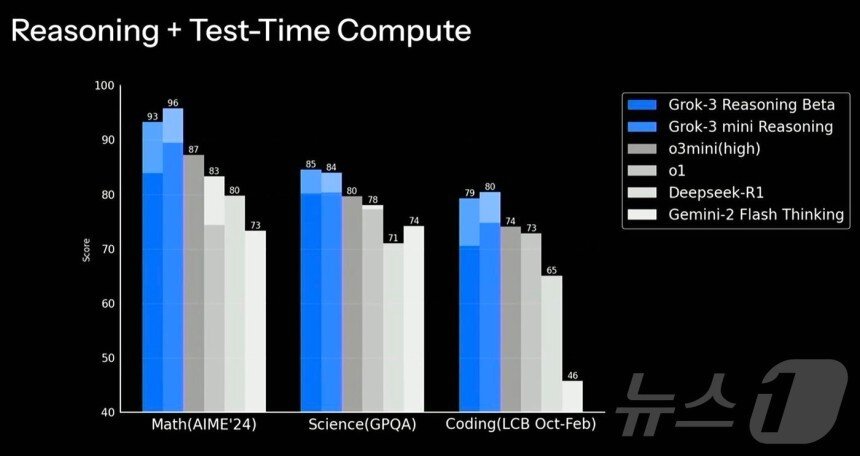
일론 머스크 CEO와 연구원들은 그록3와 그록3미니가 수학·과학·코딩 테스트에서 경쟁모델보다 더 높은 점수를 기록했다고 언급했다.(영상 갈무리)일론 머스크 CEO와 연구원들은 그록3 베타와 그록3 미니 버전이 '테스트타임컴퓨트' 테스트에서 경쟁모델보다 더 높은 점수를 기록했다고 언급했다.(영상 갈무리)일론 머스크 xAI CEO 그록3 공개관련 키워드챗GPT그록3AI샘올트먼전문가일론머스크트위터김민석 기자 "소라만 마블·픽사 맘껏 허용"…오픈AI·디즈니 동맹 구글에 칼날구글·메타 '파이토치-TPU 연동' 동맹…GPU 독점체제 균열 가속관련 기사韓 AI 모델 수능수학 풀이했더니…챗GPT·제미나이·딥시크와 격차中 '키미-K2' 도발에 美 최신모델 잇단출격…또 '딥시크 모먼트'"AI 비서가 직원처럼? 10년은 일러"…오픈AI 공동창업자의 찬물서울시, 29개 생성형AI 모델 도입…'용량제' 시범 운영WP "가장 정확한 AI 답변은 '구글 AI 모드'…챗GPT·퍼플렉 제쳐"